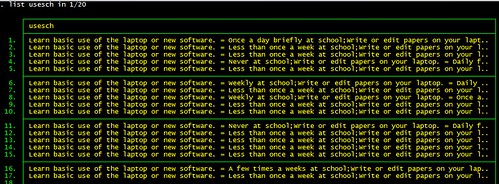
今天拿到一個要分析的問卷,不看不知道,一看快昏倒,裡面有一題問卷的回答像下面一樣:
變數裡面全部是 string,這也就算了。一個 string 裡面包含了五個問題,每個問題有五個選項,這還讓不讓人活啊?這樣是沒辦法跑任何分析的,得先將五個問題分開,然後再將五個答案分別 code 成 1-5,這才有辦法作分析。
雖說有萬般的不幸,但這資料裡面有個好處:格式差不多。像下面一樣:
問題.= xxx; 問題. =ooo; 問題. =oxox;
也就是說,每個問題以「;」 作結尾,所以只要將這個變數依照 ; 的位置分割成五個部分,那接下來就容易了。
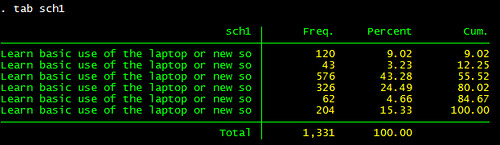
這指令很簡單,就是 split。split 後面接的是這個變數,分號之後 p () 裡面的值是「規則」,也就是要找哪個字串來切割,依此例來說就是 ; 。分割完之後,我要 stata 幫我產生以 sch 為開頭的變數,所以附加了 gen 指令,所以整個指令如下圖:
split usesch, p(";") gen(sch) 成果如下:
接下來的動作就是用 recode 將 string 改成 1-5,然後用 destring 就行了。
小技巧,對處理複雜的資料很有幫助的。
標籤: 統計分析