人在寫報告的時候,總是會有一堆奇思幻想。關於報告本身的聯想與進展並不多,想的都是一些有的沒的。小的在下為了推廣Stata,並為了娛樂大家,不惜犧牲形象,想出勁爆話題,讓大家學習統計時,印象更加深刻。請不要以有色眼光看待此kuso研究和想出這研究的人…
所用的資料庫仍是Stata: 敘述統計(descriptive statistics)所用的GSS 2000。一開始資料要做很多recode和產生很多虛擬變項(dummy variable),這方面不熟的就從Stata: 敘述統計(descriptive statistics) 看起。變數後面括號的英文為該變數在GSS 2000裡的variable name。
我們想知道的是:有什麼因素可以預測性伴侶人數(partners)?很直覺的就會想到幾個因素:種族(race)、年紀(age)、收入(income)、性別(sex)、婚姻狀況(marital)。
如果是這樣,就不叫惡搞了 XD 所以小弟想了兩個假設:
當控制了上述變數之後:
1. 是否愈快樂(happy)的人,性伴侶愈多?
2. 愈常聽到其它語言的人(langcom),性伴侶愈多?
這是什麼鬼題目?每周聽到多少次其它語言,跟性伴侶人數有什麼關係?廢話,就是要奇怪,不然哪叫惡搞?
接下來要做的第一件事:處理categorical variables。處理的程式如下:
use http://twtcsl.org/dataset/gss2000.dta
tab sex, gen(dmale)
rename dmale1 dmale
drop dmale2
gen dpartners=.
replace dpartners=0 if partners==0
replace dpartners=1 if partners==1
replace dpartners=2 if partners==2
replace dpartners=3 if partners==3
replace dpartners=4 if partners==4
replace dpartners=7.5 if partners==5
replace dpartners=15 if partners==6
gen dlangcom=.
replace dlangcom=0 if langcom==1
replace dlangcom=0.5 if langcom==2
replace dlangcom=1 if langcom==3
replace dlangcom=3.5 if langcom==4
replace dlangcom=7 if langcom==5
replace dlangcom=14 if langcom==6
gen dincome=.
replace dincome=0 if income==0
replace dincome=500 if income==1
replace dincome=1500 if income==2
replace dincome=3500 if income==3
replace dincome=4500 if income==4
replace dincome=5500 if income==5
replace dincome=6500 if income==6
replace dincome=7500 if income==7
replace dincome=9000 if income==8
replace dincome=12500 if income==9
replace dincome=17500 if income==10
replace dincome=22500 if income==11
replace dincome=27500 if income==12
tab race, gen(d)
rename d1 dwhite
rename d2 dblack
rename d3 dother
tab marital, gen(d)
rename d1 dmarried
rename d2 dwidowed
rename d3 ddivorced
rename d4 dseparated
rename d5 dnevermarried
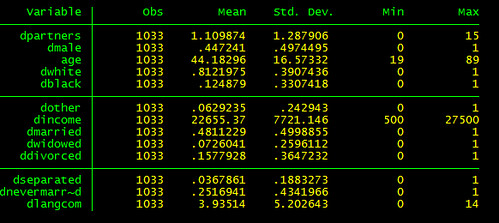
sum dpartners dmale age dwhite dblack dother dincome dmarried dwidowed ddivorced dseparated dnevermarried dlangcom if (dwidowed!=.) & (ddivorced!=.) & (dseparated!=.) & (dnevermarried!=.)& (happy<.) & (dlangcom!=.) & (dpartners<.) & (age<.) & (dincome<.)這裡有個小技巧:如果你的categorical variable是一個數字範圍,比如說年紀是12-15,或是薪水是10000-19999。不論數字範圍是否一樣大,通常的作法就是第一組叫1,第二組叫2。這樣的缺點就是跑迴歸(regression)後的結果有點難解讀,因為不能確定增加1是增加多少,特別是組間大小不一時。另外一種作法就是:取組的平均值,像年紀是12-15歲,就取個平均值13.5歲。這樣我們就知道增加一歲會對依變項有多大的影響。我上面的作法就是這一種。
最後出來的結果應該像這樣:
至於分析,有興趣的可以先偷跑regression,不然就下回分解 XD
標籤: 統計分析