問卷常會有像這樣的複選題(multiple responses):
問題:你為什麼來看研究生2.0的文章?(選擇所有適合的)
□ 因為自己也是研究生 □ 朋友介紹的網站
□ 從搜尋引擎找到的 □ 亂入的
如果你是在surveymonkey之類的網站製作的問卷,通常會把這個問題的4個選項分成4個欄位,每個欄位像dummy variable一樣,是的話是1,不是的話是0。所以全選的話,欄位值分別是1、1、1、1,只選第一個的話,則是1、0、0、0。
到這裡很多人都會,問題是:下一步怎麼辦?要用什麼方式分析呢?
如果你把這個選項當作是outcome variable,想要看不同年齡、性別、社經地位的人,是否因為不同的目的來看本站,那你要的就是Logistic regression。
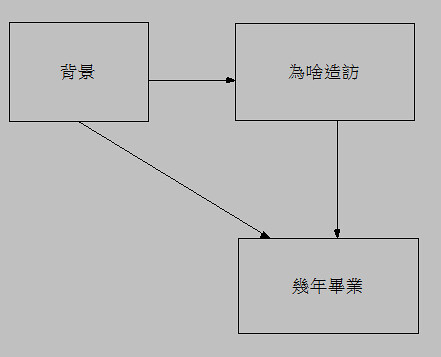
什麼?你還要複雜一點嗎?那我們先畫個示意圖好了:
我們可以用結構方程模式(SEM)的觀念畫一個示意圖。我們認為個人背景會影響為什麼造訪(ex: 男性多半因為自己是研究生,女性多半因為朋友介紹的),而為什麼造訪本站會影響你幾年畢業(其實再加一個為什麼造訪可解釋用功程度,而用功程度可解釋幾年畢業,不過既然是範例,簡單一點就畫這樣好了)。
要怎麼做呢?首先你應該作一個descriptive analysis的表格,把你的變數全放進去。要表格範本可以到統計表格範本這篇文章找,想直接從stata輸出表格到word的話看這篇。
作完表格一之後,表格二是作logistic regression,背景是independent variable,為什麼造訪是depedent variable,然後把迴歸的表格畫出來,就是表格二。我們有4個選項,意思是這4個選項要各跑一次,一共要跑4次,但你的表格可以把它合成一個。
接下來是表格三。表格三比較複雜,因為有兩條regression line到幾年畢業。我們對背景影響幾年畢業其實並沒有興趣,只是想控制這些變數,看看控制這些變數之後,造訪本網站是否可解釋幾年畢業。所以你先要跑一個linear regression,把背景放成independent variable,幾年畢業為dependent variable,這個regression就是你的model 1。你的model2 則是將背景與造訪本站的原因同時放入,dependent variable則不變。你想看的是加入了這些之後,有什麼變化,是否解釋的比例更高,這些因素是否為顯著差異。
我試著盡力用簡單的語言解釋了,如果看不懂,歡迎指出哪裡看不懂。如果不懂什麼是logistic regression,那請先google一下,我最近爆忙還沒有空寫。
標籤: 統計分析